zstd v1.4.5 Release Notes
Release Date: 2020-05-22 // almost 4 years ago-
🚀 Zstd v1.4.5 Release Notes
🚀 This is a fairly important release which includes performance improvements and new major CLI features. It also fixes a few corner cases, making it a recommended upgrade.
Faster Decompression Speed
Decompression speed has been improved again, thanks to great contributions from @terrelln.
As usual, exact mileage varies depending on files and compilers.
Forx64cpus, expect a speed bump of at least +5%, and up to +10% in favorable cases.
ARMcpus receive more benefit, with speed improvements ranging from +15% vicinity, and up to +50% for certain SoCs and scenarios (ARM‘s situation is more complex due to larger differences in SoC designs).For illustration, some benchmarks run on a modern
x64platform usingzstd -bcompiled withgccv9.3.0 :v1.4.4 v1.4.5 silesia.tar 1568 MB/s 1653 MB/s --- --- --- enwik8 1374 MB/s 1469 MB/s calgary.tar 1511 MB/s 1610 MB/s Same platform, using
clangv10.0.0 compiler :v1.4.4 v1.4.5 silesia.tar 1439 MB/s 1496 MB/s --- --- --- enwik8 1232 MB/s 1335 MB/s calgary.tar 1361 MB/s 1457 MB/s Simplified integration
Presuming a project needs to integrate
libzstd's source code (as opposed to linking a pre-compiled library), the/libsource directory can be copy/pasted into target project. Then the local build system must setup a few include directories. Some setups are automatically provided in prepared build scripts, such asMakefile, but any other 3rd party build system must do it on its own.
This integration is now simplified, thanks to @felixhandte, by making all dependencies within/librelative, meaning it’s only necessary to setup include directories for the*.hheader files that are directly included into target project (typicallyzstd.h). Even that task can be circumvented by copy/pasting the*.hinto already established include directories.Alternatively, if you are a fan of one-file integration strategy, @cwoffenden has extended his one-file decoder script into a full feature one-file compression library. The script
create_single_file_library.shwill generate a filezstd.c, which contains all selected elements from the library (by default, compression and decompression). It’s then enough to import justzstd.hand the generatedzstd.cinto target project to access all included capabilities.--patch-from💻 Zstandard CLI is introducing a new command line option
--patch-from, which leverages existing compressors, dictionaries and long range match finder to deliver a high speed engine for producing and applying patches to files.👍
--patch-fromis based on dictionary compression. It will consider a previous version of a file as a dictionary, to better compress a new version of same file. This operation preserves fastzstdspeeds at lower compression levels. To this ends, it also increases the previous maximum limit for dictionaries from 32 MB to 2 GB, and automatically uses the long range match finder when needed (though it can also be manually overruled).
--patch-fromcan also be combined with multi-threading mode at a very minimal compression ratio loss.Example usage:
`# create the patch zstd --patch-from=<oldfile> <newfile> -o <patchfile> # apply the patch zstd -d --patch-from=<oldfile> <patchfile> -o <newfile>`Benchmarks:
✅ We comparedzstdtobsdiff, a popular industry grade diff engine. Our test corpus were tarballs of different versions of source code from popular GitHub repositories. Specifically:`repos = { # ~31mb (small file) "zstd": {"url": "https://github.com/facebook/zstd", "dict-branch": "refs/tags/v1.4.2", "src-branch": "refs/tags/v1.4.3"}, # ~273mb (medium file) "wordpress": {"url": "https://github.com/WordPress/WordPress", "dict-branch": "refs/tags/5.3.1", "src-branch": "refs/tags/5.3.2"}, # ~1.66gb (large file) "llvm": {"url": "https://github.com/llvm/llvm-project", "dict-branch": "refs/tags/llvmorg-9.0.0", "src-branch": "refs/tags/llvmorg-9.0.1"} }`--patch-fromon level 19 (with chainLog=30 and targetLength=4kb) is comparable withbsdiffwhen comparing patch sizes.
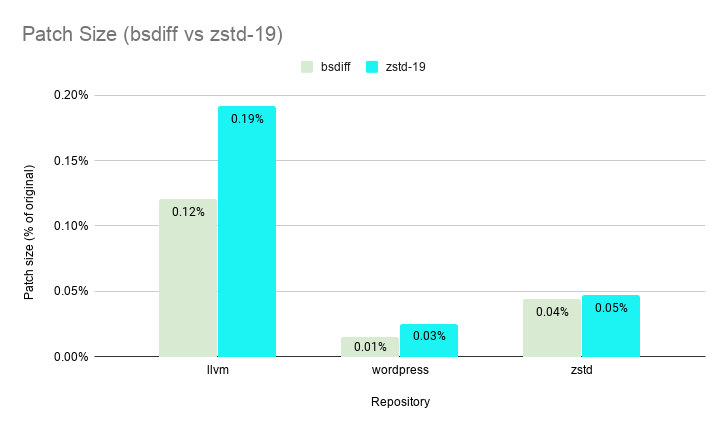
--patch-fromgreatly outperformsbsdiffin speed even on its slowest setting of level 19 boasting an average speedup of ~7X.--patch-fromis >200X faster on level 1 and >100X faster (shown below) on level 3 vsbsdiffwhile still delivering patch sizes less than 0.5% of the original file size.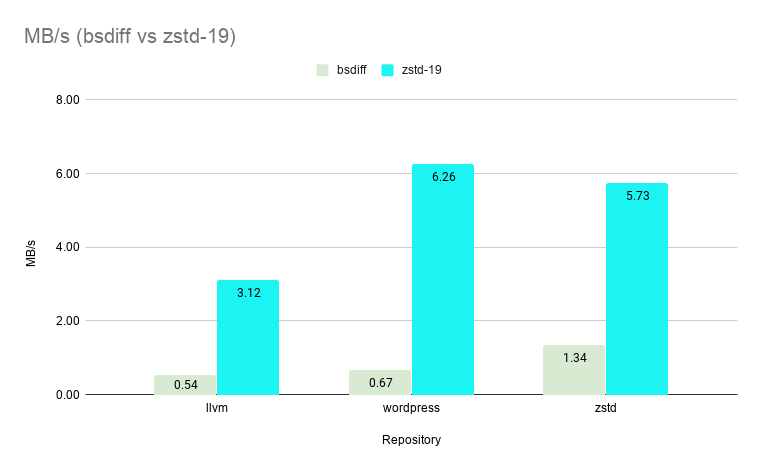
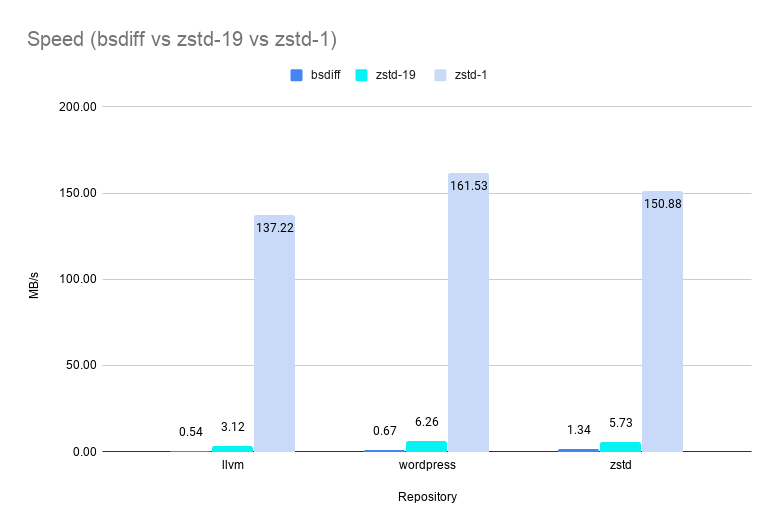
And of course, there is no change to the fast zstd decompression speed.
--filelist=Finally,
--filelist=is a new CLI capability, which makes it possible to pass a list of files to operate upon from a file,
💻 as opposed to listing all target files solely on the command line.
This makes it possible to prepare a list offline, save it into a file, and then provide the prepared list tozstd.
💻 Another advantage is that this method circumvents command line size limitations, which can become a problem when operating on very large directories (such situation can typically happen with shell expansion).
🆓 In contrast, passing a very large list of filenames from within a file is free of such size limitation.Full List
- perf: Improved decompression speed (x64 >+5%, ARM >+15%), by @terrelln
- perf: Automatically downsizes
ZSTD_DCtxwhen too large for too long (#2069, by @bimbashreshta) - perf: Improved fast compression speed on
aarch64(#2040, ~+3%, by @caoyzh) - perf: Small level 1 compression speed gains (depending on compiler)
- 🛠 fix: Compression ratio regression on huge files (> 3 GB) using high levels (
--ultra) and multithreading, by @terrelln - api:
ZDICT_finalizeDictionary()is promoted to stable (#2111) - api: new experimental parameter
ZSTD_d_stableOutBuffer(#2094) - 🏗 build: Generate a single-file
libzstdlibrary (#2065, by @cwoffenden) - 🏗 build: Relative includes, no longer require
-Iflags forzstdlib subdirs (#2103, by @felixhandte) - 🏗 build:
zstdnow compiles cleanly under-pedantic(#2099) - 🏗 build:
zstdnow compiles with make-4.3 - 🐧 build: Support
mingwcross-compilation from Linux, by @Ericson2314 - 🏁 build: Meson multi-thread build fix on windows
- 🏗 build: Some misc
iccfixes backed by new ci test on travis - cli: New
--patch-fromcommand, create and apply patches from files, by @bimbashreshta - cli:
--filelist=: Provide a list of files to operate upon from a file - cli:
-bcan now benchmark multiple files in decompression mode - cli: New
--no-content-sizecommand - 0️⃣ cli: New
--show-default-cparamscommand - misc: new diagnosis tool,
checked_flipped_bits, incontrib/, by @felixhandte - misc: Extend largeNbDicts benchmark to compression
- misc: experimental edit-distance match finder in
contrib/ - 📄 doc: Improved beginner
CONTRIBUTING.mddocs - doc: New issue templates for zstd
Previous changes from v1.4.4
-
🚀 This release includes some major performance improvements and new CLI features, which make it a recommended upgrade.
Faster Decompression Speed
Decompression speed has been substantially improved, thanks to @terrelln. Exact mileage obviously varies depending on files and scenarios, but the general expectation is a bump of about +10%. The benefit is considered applicable to all scenarios, and will be perceptible for most usages.
Some benchmark figures for illustration:
v1.4.3 v1.4.4 silesia.tar 1440 MB/s 1600 MB/s enwik8 1225 MB/s 1390 MB/s calgary.tar 1360 MB/s 1530 MB/s Faster Compression Speed when Re-Using Contexts
In server workloads (characterized by very high compression volume of relatively small inputs), the allocation and initialization of
zstd's internal datastructures can become a significant part of the cost of compression. For this reason,zstdhas long had an optimization (which we recommended for large-scale users, perhaps with something like this): when you provide an already-usedZSTD_CCtxto a compression operation,zstdtries to re-use the existing data structures, if possible, rather than re-allocate and re-initialize them.🚀 Historically, this optimization could avoid re-allocation most of the time, but required an exact match of internal parameters to avoid re-initialization. In this release, @felixhandte removed the dependency on matching parameters, allowing the full context re-use optimization to be applied to effectively all compressions. Practical workloads on small data should expect a ~3% speed-up.
🐎 In addition to improving average performance, this change also has some nice side-effects on the extremes of performance.
- 🐎 On the fast end, it is now easier to get optimal performance from
zstd. In particular, it is no longer necessary to do careful tracking and matching of contexts to compressions based on detailed parameters (as discussed for example in #1796). Instead, straightforwardly reusing contexts is now optimal. - Second, this change ameliorates some rare, degenerate scenarios (e.g., high volume streaming compression of small inputs with varying, high compression levels), in which it was possible for the allocation and initialization work to vastly overshadow the actual compression work. These cases are up to 40x faster, and now perform in-line with similar happy cases.
Dictionaries and Large Inputs
In theory, using a dictionary should always be beneficial. However, due to some long-standing implementation limitations, it can actually be detrimental. Case in point: by default, dictionaries are prepared to compress small data (where they are most useful). When this prepared dictionary is used to compress large data, there is a mismatch between the prepared parameters (targeting small data) and the ideal parameters (that would target large data). This can cause dictionaries to counter-intuitively result in a lower compression ratio when compressing large inputs.
Starting with v1.4.4, using a dictionary with a very large input will no longer be detrimental. Thanks to a patch from @senhuang42, whenever the library notices that input is sufficiently large (relative to dictionary size), the dictionary is re-processed, using the optimal parameters for large data, resulting in improved compression ratio.
The capability is also exposed, and can be manually triggered using
ZSTD_dictForceLoad.🆕 New commands
zstdCLI extends its capabilities, providing new advanced commands, thanks to great contributions :zstdgenerated files (compressed or decompressed) can now be automatically stored into a different directory than the source one, using--output-dir-flat=DIRcommand, provided by @senhuang42 .- 🐎 It’s possible to inform
zstdabout the size of data coming fromstdin. @nmagerko proposed 2 new commands, allowing users to provide the exact stream size (--stream-size=#) or an approximative one (--size-hint=#). Both only make sense when compressing a data stream from a pipe (such asstdin), since for a real file,zstdobtains the exact source size from the file system. Providing a source size allowszstdto better adapt internal compression parameters to the input, resulting in better performance and compression ratio. Additionally, providing the precise size makes it possible to embed this information in the compressed frame header, which also allows decoder optimizations. - In situations where the same directory content get regularly compressed, with the intention to only compress new files not yet compressed, it’s necessary to filter the file list, to exclude already compressed files. This process is simplified with command
--exclude-compressed, provided by @shashank0791 . As the name implies, it simply excludes all compressed files from the list to process.
🌐 Single-File Decoder with Web Assembly
🏗 Let’s complete the picture with an impressive contribution from @cwoffenden.
libzstdhas long offered the capability to build only the decoder, in order to generate smaller binaries that can be more easily embedded into memory-constrained devices and applications.🏗 @cwoffenden built on this capability and offers a script creating a single-file decoder, as an amalgamated variant of reference Zstandard’s decoder. The package is completed with a nice build script, which compiles the one-file decoder into
WASMcode, for embedding into web application, and even tests it.As a capability example, check out the awesome WebGL demo provided by @cwoffenden in
/contrib/single_file_decoder/examplesdirectory!Full List
- perf: Improved decompression speed, by > 10%, by @terrelln
- 👍 perf: Better compression speed when re-using a context, by @felixhandte
- perf: Fix compression ratio when compressing large files with small dictionary, by @senhuang42
- perf:
zstdreference encoder can generateRLEblocks, by @bimbashrestha - perf: minor generic speed optimization, by @davidbolvansky
- 📜 api: new ability to extract sequences from the parser for analysis, by @bimbashrestha
- 🛠 api: fixed decoding of magic-less frames, by @terrelln
- api: fixed
ZSTD_initCStream_advanced()performance with fast modes, reported by @QrczakMK - 👍 cli: Named pipes support, by @bimbashrestha
- 👍 cli: short tar's extension support, by @stokito
- cli: command
--output-dir-flat=DIE, generates target files into requested directory, by @senhuang42 - cli: commands
--stream-size=#and--size-hint=#, by @nmagerko - cli: command
--exclude-compressed, by @shashank0791 - ✅ cli: faster
-ttest mode - cli: improved some error messages, by @vangyzen
- 🏗 cli: fix rare deadlock condition within dictionary builder, by @terrelln
- 🏗 build: single-file decoder with emscripten compilation script, by @cwoffenden
- 🏗 build: fixed
zlibWrappercompilation on Visual Studio, reported by @bluenlive - 🏗 build: fixed deprecation warning for certain gcc version, reported by @jasonma163
- 🏗 build: fix compilation on old gcc versions, by @cemeyer
- 🏗 build: improved installation directories for cmake script, by Dmitri Shubin
- 👍 pack: modified
pkgconfig, for better integration into openwrt, requested by @neheb - misc: Improved documentation :
ZSTD_CLEVEL,DYNAMIC_BMI2,ZSTD_CDict, function deprecation, zstd format - 🚚 misc: fixed educational decoder : accept larger literals section, and removed
UNALIGNED()macro
- 🐎 On the fast end, it is now easier to get optimal performance from