Changelog History
Page 1
-
v1.4.5 Changes
May 22, 2020🚀 Zstd v1.4.5 Release Notes
🚀 This is a fairly important release which includes performance improvements and new major CLI features. It also fixes a few corner cases, making it a recommended upgrade.
Faster Decompression Speed
Decompression speed has been improved again, thanks to great contributions from @terrelln.
As usual, exact mileage varies depending on files and compilers.
Forx64cpus, expect a speed bump of at least +5%, and up to +10% in favorable cases.
ARMcpus receive more benefit, with speed improvements ranging from +15% vicinity, and up to +50% for certain SoCs and scenarios (ARM‘s situation is more complex due to larger differences in SoC designs).For illustration, some benchmarks run on a modern
x64platform usingzstd -bcompiled withgccv9.3.0 :v1.4.4 v1.4.5 silesia.tar 1568 MB/s 1653 MB/s --- --- --- enwik8 1374 MB/s 1469 MB/s calgary.tar 1511 MB/s 1610 MB/s Same platform, using
clangv10.0.0 compiler :v1.4.4 v1.4.5 silesia.tar 1439 MB/s 1496 MB/s --- --- --- enwik8 1232 MB/s 1335 MB/s calgary.tar 1361 MB/s 1457 MB/s Simplified integration
Presuming a project needs to integrate
libzstd's source code (as opposed to linking a pre-compiled library), the/libsource directory can be copy/pasted into target project. Then the local build system must setup a few include directories. Some setups are automatically provided in prepared build scripts, such asMakefile, but any other 3rd party build system must do it on its own.
This integration is now simplified, thanks to @felixhandte, by making all dependencies within/librelative, meaning it’s only necessary to setup include directories for the*.hheader files that are directly included into target project (typicallyzstd.h). Even that task can be circumvented by copy/pasting the*.hinto already established include directories.Alternatively, if you are a fan of one-file integration strategy, @cwoffenden has extended his one-file decoder script into a full feature one-file compression library. The script
create_single_file_library.shwill generate a filezstd.c, which contains all selected elements from the library (by default, compression and decompression). It’s then enough to import justzstd.hand the generatedzstd.cinto target project to access all included capabilities.--patch-from💻 Zstandard CLI is introducing a new command line option
--patch-from, which leverages existing compressors, dictionaries and long range match finder to deliver a high speed engine for producing and applying patches to files.👍
--patch-fromis based on dictionary compression. It will consider a previous version of a file as a dictionary, to better compress a new version of same file. This operation preserves fastzstdspeeds at lower compression levels. To this ends, it also increases the previous maximum limit for dictionaries from 32 MB to 2 GB, and automatically uses the long range match finder when needed (though it can also be manually overruled).
--patch-fromcan also be combined with multi-threading mode at a very minimal compression ratio loss.Example usage:
`# create the patch zstd --patch-from=<oldfile> <newfile> -o <patchfile> # apply the patch zstd -d --patch-from=<oldfile> <patchfile> -o <newfile>`Benchmarks:
✅ We comparedzstdtobsdiff, a popular industry grade diff engine. Our test corpus were tarballs of different versions of source code from popular GitHub repositories. Specifically:`repos = { # ~31mb (small file) "zstd": {"url": "https://github.com/facebook/zstd", "dict-branch": "refs/tags/v1.4.2", "src-branch": "refs/tags/v1.4.3"}, # ~273mb (medium file) "wordpress": {"url": "https://github.com/WordPress/WordPress", "dict-branch": "refs/tags/5.3.1", "src-branch": "refs/tags/5.3.2"}, # ~1.66gb (large file) "llvm": {"url": "https://github.com/llvm/llvm-project", "dict-branch": "refs/tags/llvmorg-9.0.0", "src-branch": "refs/tags/llvmorg-9.0.1"} }`--patch-fromon level 19 (with chainLog=30 and targetLength=4kb) is comparable withbsdiffwhen comparing patch sizes.
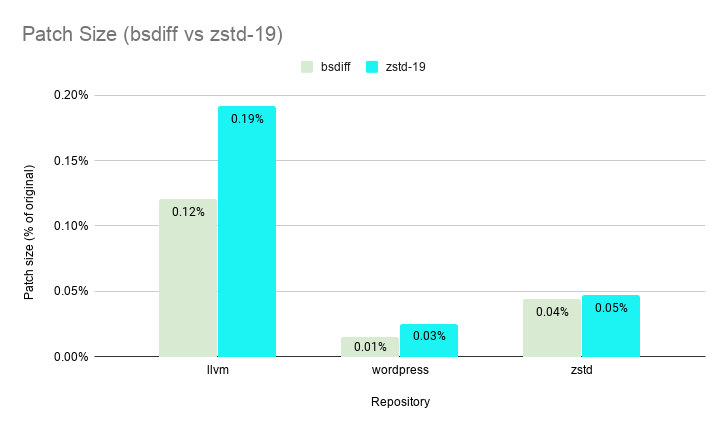
--patch-fromgreatly outperformsbsdiffin speed even on its slowest setting of level 19 boasting an average speedup of ~7X.--patch-fromis >200X faster on level 1 and >100X faster (shown below) on level 3 vsbsdiffwhile still delivering patch sizes less than 0.5% of the original file size.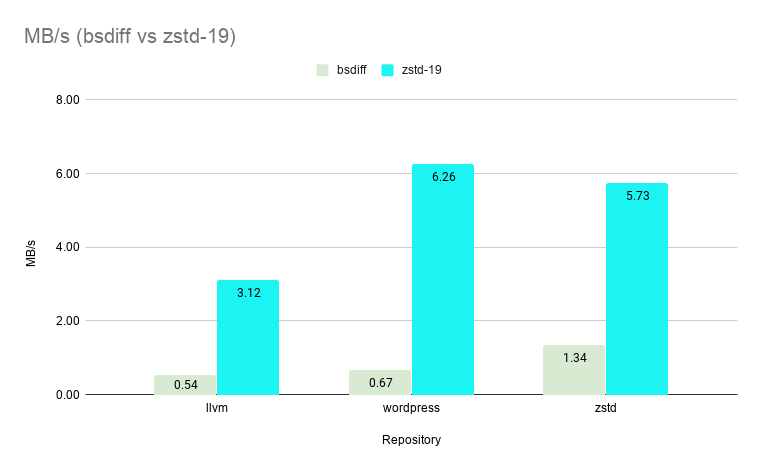
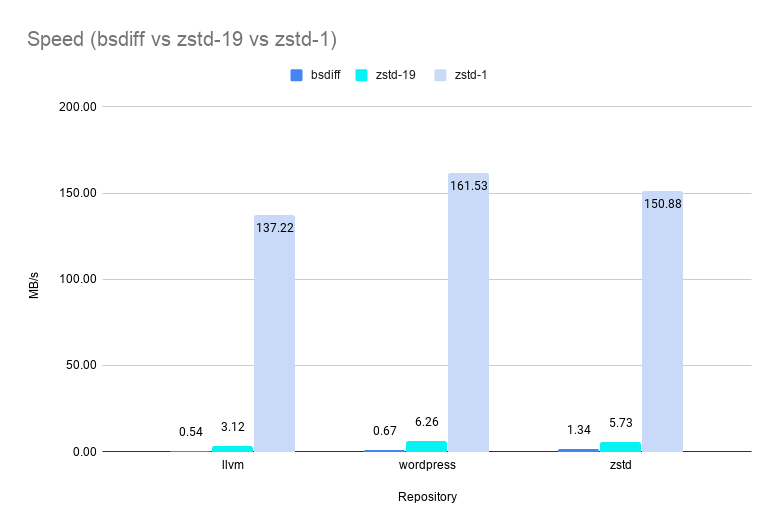
And of course, there is no change to the fast zstd decompression speed.
--filelist=Finally,
--filelist=is a new CLI capability, which makes it possible to pass a list of files to operate upon from a file,
💻 as opposed to listing all target files solely on the command line.
This makes it possible to prepare a list offline, save it into a file, and then provide the prepared list tozstd.
💻 Another advantage is that this method circumvents command line size limitations, which can become a problem when operating on very large directories (such situation can typically happen with shell expansion).
🆓 In contrast, passing a very large list of filenames from within a file is free of such size limitation.Full List
- perf: Improved decompression speed (x64 >+5%, ARM >+15%), by @terrelln
- perf: Automatically downsizes
ZSTD_DCtxwhen too large for too long (#2069, by @bimbashreshta) - perf: Improved fast compression speed on
aarch64(#2040, ~+3%, by @caoyzh) - perf: Small level 1 compression speed gains (depending on compiler)
- 🛠 fix: Compression ratio regression on huge files (> 3 GB) using high levels (
--ultra) and multithreading, by @terrelln - api:
ZDICT_finalizeDictionary()is promoted to stable (#2111) - api: new experimental parameter
ZSTD_d_stableOutBuffer(#2094) - 🏗 build: Generate a single-file
libzstdlibrary (#2065, by @cwoffenden) - 🏗 build: Relative includes, no longer require
-Iflags forzstdlib subdirs (#2103, by @felixhandte) - 🏗 build:
zstdnow compiles cleanly under-pedantic(#2099) - 🏗 build:
zstdnow compiles with make-4.3 - 🐧 build: Support
mingwcross-compilation from Linux, by @Ericson2314 - 🏁 build: Meson multi-thread build fix on windows
- 🏗 build: Some misc
iccfixes backed by new ci test on travis - cli: New
--patch-fromcommand, create and apply patches from files, by @bimbashreshta - cli:
--filelist=: Provide a list of files to operate upon from a file - cli:
-bcan now benchmark multiple files in decompression mode - cli: New
--no-content-sizecommand - 0️⃣ cli: New
--show-default-cparamscommand - misc: new diagnosis tool,
checked_flipped_bits, incontrib/, by @felixhandte - misc: Extend largeNbDicts benchmark to compression
- misc: experimental edit-distance match finder in
contrib/ - 📄 doc: Improved beginner
CONTRIBUTING.mddocs - doc: New issue templates for zstd
-
v1.4.4 Changes
November 05, 2019🚀 This release includes some major performance improvements and new CLI features, which make it a recommended upgrade.
Faster Decompression Speed
Decompression speed has been substantially improved, thanks to @terrelln. Exact mileage obviously varies depending on files and scenarios, but the general expectation is a bump of about +10%. The benefit is considered applicable to all scenarios, and will be perceptible for most usages.
Some benchmark figures for illustration:
v1.4.3 v1.4.4 silesia.tar 1440 MB/s 1600 MB/s enwik8 1225 MB/s 1390 MB/s calgary.tar 1360 MB/s 1530 MB/s Faster Compression Speed when Re-Using Contexts
In server workloads (characterized by very high compression volume of relatively small inputs), the allocation and initialization of
zstd's internal datastructures can become a significant part of the cost of compression. For this reason,zstdhas long had an optimization (which we recommended for large-scale users, perhaps with something like this): when you provide an already-usedZSTD_CCtxto a compression operation,zstdtries to re-use the existing data structures, if possible, rather than re-allocate and re-initialize them.🚀 Historically, this optimization could avoid re-allocation most of the time, but required an exact match of internal parameters to avoid re-initialization. In this release, @felixhandte removed the dependency on matching parameters, allowing the full context re-use optimization to be applied to effectively all compressions. Practical workloads on small data should expect a ~3% speed-up.
🐎 In addition to improving average performance, this change also has some nice side-effects on the extremes of performance.
- 🐎 On the fast end, it is now easier to get optimal performance from
zstd. In particular, it is no longer necessary to do careful tracking and matching of contexts to compressions based on detailed parameters (as discussed for example in #1796). Instead, straightforwardly reusing contexts is now optimal. - Second, this change ameliorates some rare, degenerate scenarios (e.g., high volume streaming compression of small inputs with varying, high compression levels), in which it was possible for the allocation and initialization work to vastly overshadow the actual compression work. These cases are up to 40x faster, and now perform in-line with similar happy cases.
Dictionaries and Large Inputs
In theory, using a dictionary should always be beneficial. However, due to some long-standing implementation limitations, it can actually be detrimental. Case in point: by default, dictionaries are prepared to compress small data (where they are most useful). When this prepared dictionary is used to compress large data, there is a mismatch between the prepared parameters (targeting small data) and the ideal parameters (that would target large data). This can cause dictionaries to counter-intuitively result in a lower compression ratio when compressing large inputs.
Starting with v1.4.4, using a dictionary with a very large input will no longer be detrimental. Thanks to a patch from @senhuang42, whenever the library notices that input is sufficiently large (relative to dictionary size), the dictionary is re-processed, using the optimal parameters for large data, resulting in improved compression ratio.
The capability is also exposed, and can be manually triggered using
ZSTD_dictForceLoad.🆕 New commands
zstdCLI extends its capabilities, providing new advanced commands, thanks to great contributions :zstdgenerated files (compressed or decompressed) can now be automatically stored into a different directory than the source one, using--output-dir-flat=DIRcommand, provided by @senhuang42 .- 🐎 It’s possible to inform
zstdabout the size of data coming fromstdin. @nmagerko proposed 2 new commands, allowing users to provide the exact stream size (--stream-size=#) or an approximative one (--size-hint=#). Both only make sense when compressing a data stream from a pipe (such asstdin), since for a real file,zstdobtains the exact source size from the file system. Providing a source size allowszstdto better adapt internal compression parameters to the input, resulting in better performance and compression ratio. Additionally, providing the precise size makes it possible to embed this information in the compressed frame header, which also allows decoder optimizations. - In situations where the same directory content get regularly compressed, with the intention to only compress new files not yet compressed, it’s necessary to filter the file list, to exclude already compressed files. This process is simplified with command
--exclude-compressed, provided by @shashank0791 . As the name implies, it simply excludes all compressed files from the list to process.
🌐 Single-File Decoder with Web Assembly
🏗 Let’s complete the picture with an impressive contribution from @cwoffenden.
libzstdhas long offered the capability to build only the decoder, in order to generate smaller binaries that can be more easily embedded into memory-constrained devices and applications.🏗 @cwoffenden built on this capability and offers a script creating a single-file decoder, as an amalgamated variant of reference Zstandard’s decoder. The package is completed with a nice build script, which compiles the one-file decoder into
WASMcode, for embedding into web application, and even tests it.As a capability example, check out the awesome WebGL demo provided by @cwoffenden in
/contrib/single_file_decoder/examplesdirectory!Full List
- perf: Improved decompression speed, by > 10%, by @terrelln
- 👍 perf: Better compression speed when re-using a context, by @felixhandte
- perf: Fix compression ratio when compressing large files with small dictionary, by @senhuang42
- perf:
zstdreference encoder can generateRLEblocks, by @bimbashrestha - perf: minor generic speed optimization, by @davidbolvansky
- 📜 api: new ability to extract sequences from the parser for analysis, by @bimbashrestha
- 🛠 api: fixed decoding of magic-less frames, by @terrelln
- api: fixed
ZSTD_initCStream_advanced()performance with fast modes, reported by @QrczakMK - 👍 cli: Named pipes support, by @bimbashrestha
- 👍 cli: short tar's extension support, by @stokito
- cli: command
--output-dir-flat=DIE, generates target files into requested directory, by @senhuang42 - cli: commands
--stream-size=#and--size-hint=#, by @nmagerko - cli: command
--exclude-compressed, by @shashank0791 - ✅ cli: faster
-ttest mode - cli: improved some error messages, by @vangyzen
- 🏗 cli: fix rare deadlock condition within dictionary builder, by @terrelln
- 🏗 build: single-file decoder with emscripten compilation script, by @cwoffenden
- 🏗 build: fixed
zlibWrappercompilation on Visual Studio, reported by @bluenlive - 🏗 build: fixed deprecation warning for certain gcc version, reported by @jasonma163
- 🏗 build: fix compilation on old gcc versions, by @cemeyer
- 🏗 build: improved installation directories for cmake script, by Dmitri Shubin
- 👍 pack: modified
pkgconfig, for better integration into openwrt, requested by @neheb - misc: Improved documentation :
ZSTD_CLEVEL,DYNAMIC_BMI2,ZSTD_CDict, function deprecation, zstd format - 🚚 misc: fixed educational decoder : accept larger literals section, and removed
UNALIGNED()macro
- 🐎 On the fast end, it is now easier to get optimal performance from
-
v1.4.3 Changes
August 19, 2019Dictionary Compression Regression
🚀 We discovered an issue in the v1.4.2 release, which can degrade the effectiveness of dictionary compression. This release fixes that issue.
Detailed Changes
- 🐛 bug: Fix Dictionary Compression Ratio Regression by @Cyan4973 (#1709)
- 🐛 bug: Fix Buffer Overflow in v0.3 Decompression by @felixhandte (#1722)
- 🏗 build: Add support for IAR C/C++ Compiler for Arm by @joseph0918 (#1705)
- misc: Add NULL pointer check in util.c by @LeeYoung624 (#1706)
-
v1.4.2 Changes
July 25, 2019Legacy Decompression Fix
🚀 This release is a small one, that corrects an issue discovered in the previous release. Zstandard v1.4.1 included a bug in decompressing v0.5 legacy frames, which is fixed in v1.4.2.
Detailed Changes
- 🐛 bug: Fix bug in zstd-0.5 decoder by @terrelln (#1696)
- 🐛 bug: Fix seekable decompression in-memory API by @iburinoc (#1695)
- 🐛 bug: Close minor memory leak in CLI by @LeeYoung624 (#1701)
- misc: Validate blocks are smaller than size limit by @vivekmig (#1685)
- misc: Restructure source files by @ephiepark (#1679)
-
v1.4.1 Changes
July 19, 2019🚧 Maintenance
🚀 This release is primarily a maintenance release.
0️⃣ It includes a few bug fixes, including a fix for a rare data corruption bug, which could only be triggered in a niche use case, when doing all of the following: using multithreading mode, with an overlap size >= 512 MB, using a strategy >=
ZSTD_btlazy, and compressing more than 4 GB. None of the default compression levels meet these requirements (not even--ultraones).🐎 Performance
🚀 This release also includes some performance improvements, among which the primary improvement is that Zstd decompression is ~7% faster, thanks to @mgrice.
👀 See this comparison of decompression speeds at different compression levels, measured on the Silesia Corpus, on an Intel i9-9900K with GCC 9.1.0.
Level v1.4.0 v1.4.1 Delta 1 1390 MB/s 1453 MB/s +4.5% 3 1208 MB/s 1301 MB/s +7.6% 5 1129 MB/s 1233 MB/s +9.2% 7 1224 MB/s 1347 MB/s +10.0% 16 1278 MB/s 1430 MB/s +11.8% Detailed list of changes
- 🐛 bug: Fix data corruption in niche use cases by @terrelln (#1659)
- 🐛 bug: Fuzz legacy modes, fix uncovered bugs by @terrelln (#1593, #1594, #1595)
- 🐛 bug: Fix out of bounds read by @terrelln (#1590)
- perf: Improved decoding speed by ~7% @mgrice (#1668)
- perf: Large compression ratio improvement for small
windowLogby @Cyan4973 (#1624) - perf: Faster compression speed in high compression mode for repetitive data by @terrelln (#1635)
- perf: Slightly improved compression ratio of level 3 and 4 (
ZSTD_dfast) by @Cyan4973 (#1681) - perf: Slightly faster compression speed when re-using a context by @Cyan4973 (#1658)
- api: Add parameter to generate smaller dictionaries by @Tyler-Tran (#1656)
- cli: Recognize symlinks when built in C99 mode by @felixhandte (#1640)
- cli: Expose cpu load indicator for each file on -vv mode by @ephiepark (#1631)
- cli: Restrict read permissions on destination files by @chungy (#1644)
- cli: zstdgrep: handle -f flag by @felixhandte (#1618)
- cli: zstdcat: follow symlinks by @vejnar (#1604)
- 🚚 doc: Remove extra size limit on compressed blocks by @felixhandte (#1689)
- 📚 doc: Improve documentation on streaming buffer sizes by @Cyan4973 (#1629)
- 🏗 build: CMake: support building with LZ4 @LeeYoung624 (#1626)
- 🏗 build: CMake: install zstdless and zstdgrep by @LeeYoung624 (#1647)
- 🏗 build: CMake: respect existing uninstall target by @j301scott (#1619)
- 🏗 build: Make: skip multithread tests when built without support by @michaelforney (#1620)
- 🏗 build: Make: Fix examples/ test target by @sjnam (#1603)
- 🏗 build: Meson: rename options out of deprecated namespace by @lzutao (#1665)
- 🏗 build: Meson: fix build by @lzutao (#1602)
- 🏗 build: Visual Studio: don't export symbols in static lib by @scharan (#1650)
- 🏗 build: Visual Studio: fix linking by @Absotively (#1639)
- 🏗 build: Fix MinGW-W64 build by @myzhang1029 (#1600)
- misc: Expand decodecorpus coverage by @ephiepark (#1664)
-
v1.4.0 Changes
April 16, 2019Advanced API
🚀 The main focus of the v1.4.0 release is the stabilization of the advanced API.
The advanced API provides a way to set specific parameters during compression and decompression in an API and ABI compatible way. For example, it allows you to compress with multiple threads, enable --long mode, set frame parameters, and load dictionaries. It is compatible with
ZSTD_compressStream*()andZSTD_compress2(). There is also an advanced decompression API that allows you to set parameters like maximum memory usage, and load dictionaries. It is compatible with the existing decompression functionsZSTD_decompressStream()andZSTD_decompressDCtx().👍 The old streaming functions are all compatible with the new API, and the documentation provides the equivalent function calls in the new API. For example, see
ZSTD_initCStream(). The stable functions will remain supported, but the functions in the experimental sections, likeZSTD_initCStream_usingDict(), will eventually be marked as deprecated and removed in favor of the new advanced API.⚡️ The examples have all been updated to use the new advanced API. If you have questions about how to use the new API, please refer to the examples, and if they are unanswered, please open an issue.
🐎 Performance
🐎 Zstd's fastest compression level just got faster! Thanks to ideas from Intel's igzip and @gbtucker, we've made level 1, zstd's fastest strategy, 6-8% faster in most scenarios. For example on the Silesia Corpus with level 1, we see 0.2% better compression compared to zstd-1.3.8, and these performance figures on an Intel i9-9900K:
Version C. Speed D. Speed 1.3.8 gcc-8 489 MB/s 1343 MB/s 1.4.0 gcc-8 532 MB/s (+8%) 1346 MB/s 1.3.8 clang-8 488 MB/s 1188 MB/s 1.4.0 clang-8 528 MB/s (+8%) 1216 MB/s 🆕 New Features
A new experimental function
ZSTD_decompressBound()has been added by @shakeelrao. It is useful when decompressing zstd data in a single shot that may, or may not have the decompressed size written into the frame. It is exact when the decompressed size is written into the frame, and a tight upper bound within 128 KB, as long asZSTD_e_flushandZSTD_flushStream()aren't used. WhenZSTD_e_flushis used, in the worst case the bound can be very large, but this isn't a common scenario.The parameter
ZSTD_c_literalCompressionModeand the CLI flag--[no-]compress-literalsallow users to explicitly enable and disable literal compression. By default literals are compressed with positive compression levels, and left uncompressed for negative compression levels. Disabling literal compression boosts compression and decompression speed, at the cost of compression ratio.Detailed list of changes
- perf: Improve level 1 compression speed in most scenarios by 6% by @gbtucker and @terrelln
- 🚚 api: Move the advanced API, including all functions in the staging section, to the stable section
- api: Make ZSTD_e_flush and ZSTD_e_end block for maximum forward progress
- api: Rename
ZSTD_CCtxParam_getParametertoZSTD_CCtxParams_getParameter - api: Rename
ZSTD_CCtxParam_setParametertoZSTD_CCtxParams_setParameter - 0️⃣ api: Don't export ZSTDMT functions from the shared library by default
- api: Require
ZSTD_MULTITHREADto be defined to use ZSTDMT - api: Add
ZSTD_decompressBound()to provide an upper bound on decompressed size by @shakeelrao - api: Fix
ZSTD_decompressDCtx()corner cases with a dictionary - api: Move
ZSTD_getDictID_*()functions to the stable section - api: Add
ZSTD_c_literalCompressionModeflag to enable or disable literal compression by @terrelln - api: Allow compression parameters to be set when a dictionary is used
- api: Allow setting parameters before or after
ZSTD_CCtx_loadDictionary()is called - api: Fix
ZSTD_estimateCStreamSize_usingCCtxParams() - api: Setting
ZSTD_d_maxWindowLogto0means use the default - cli: Ensure that a dictionary is not used to compress itself by @shakeelrao
- cli: Add
--[no-]compress-literalsflag to enable or disable literal compression - ⚡️ doc: Update the examples to use the advanced API
- doc: Explain how to transition from old streaming functions to the advanced API in the header
- 🚀 build: Improve the Windows release packages
- 🏗 build: Improve CMake build by @hjmjohnson
- 🏗 build: Build fixes for FreeBSD by @lwhsu
- 🏗 build: Remove redundant warnings by @thatsafunnyname
- 🏗 build: Fix tests on OpenBSD by @bket
- 👷 build: Extend fuzzer build system to work with the new clang engine
- 🏗 build: CMake now creates the
libzstd.so.1symlink - 🏗 build: Improve Menson build by @lzutao
- misc: Fix symbolic link detection on FreeBSD
- misc: Use physical core count for
-T0on FreeBSD by @cemeyer - misc: Fix
zstd --liston truncated files by @kostmo - 🌲 misc: Improve logging in debug mode by @felixhandte
- ✅ misc: Add CirrusCI tests by @lwhsu
- ⚡️ misc: Optimize dictionary memory usage in corner cases
- 🏗 misc: Improve the dictionary builder on small or homogeneous data
- misc: Fix spelling across the repo by @jsoref
-
v1.3.8 Changes
December 27, 2018Advanced API
v1.3.8main focus is the stabilization of the advanced API.This API has been in the making for more than a year, and makes it possible to trigger advanced features, such as multithreading,
--longmode, or detailed frame parameters, in a straightforward and extensible manner. Some examples are provided in this blog entry.
To make this vision possible, the advanced API relies on sticky parameters, which can be stacked on top of each other in any order. This makes it possible to introduce new features in the future without breaking API nor ABI.🚀 This API has provided a good experience in our infrastructure, and we hope it will prove easy to use and efficient in your applications. Nonetheless, before being branded "stable", this proposal must spend a last round in "staging area", in order to generate comments and feedback from new users. It's planned to be labelled "stable" by
v1.4.0, which is expected to be next release, depending on received feedback.🗄 The experimental section still contains a lot of prototypes which are largely redundant with the new advanced API. Expect them to become deprecated, and then later dropped in some future. Transition towards the newer advanced API is therefore highly recommended.
🐎 Performance
🚀 Decoding speed has been improved again, primarily for some specific scenarios : frames using large window sizes (
--ultraor--long), and cold dictionary. Cold dictionary is expected to become more important in the near future, as solutions relying on thousands of dictionaries simultaneously will be deployed.The higher compression levels get a slight compression ratio boost, mostly visible for small (<256 KB) and large (>32 MB) data streams. This change benefits asymmetric scenarios (compress ones, decompress many times), typically targeting level 19.
🆕 New features
⚡️ A noticeable addition, @terrelln introduces the
--rsyncablemode tozstd. Similar togzip --rsyncable, it generates a compressed frame which is friendly torsyncin case of limited changes : a difference in the input data will only impact a small localized amount of compressed data, instead of everything from the position onward due to cascading impacts. This is useful for very large archives regularly updated and synchronized over long distance connections (as an example, compressed mailboxes come to mind).🔀 The method used by
zstdpreserves the compression ratio very well, introducing only very tiny losses due to synchronization points, meaning it's no longer a sacrifice to use--rsyncable. Here is an example onsilesia.tar, using default compression level :compressor normal --rsyncableRatio diff. time gzip 68235456 68778265 -0.795% 7.92s zstd 66829650 66846769 -0.026% 1.17s 0️⃣ Speaking of compression of level : it's now possible to use environment variable
ZSTD_CLEVELto influence default compression level. This can prove useful in situations where it's not possible to provide command line parameters, typically whenzstdis invoked "under the hood" by some calling process.🏗 Lastly, anyone interested in embedding a small
zstddecoder into a space-constrained application will be interested in a new set of build macros introduced by @felixhandte, which makes it possible to selectively turn off decoder features to reduce binary size even further. Final binary size will of course vary depending on target assembler and compiler, but in preliminary testings on x64, it helped reducing the decoder size by a factor 3 (from ~64KB towards ~20KB).Detailed list of changes
- 👍 perf: better decompression speed on large files (+7%) and cold dictionaries (+15%)
- 👍 perf: slightly better compression ratio at high compression modes
- api : finalized advanced API, last stage before "stable" status
- api : new
--rsyncablemode, by @terrelln - 👍 api : support decompression of empty frames into
NULL(used to be an error) (#1385) - 🏗 build: new set of build macros to generate a minimal size decoder, by @felixhandte
- 🏗 build: fix compilation on MIPS32, reported by @clbr (#1441)
- 🏗 build: fix compilation with multiple -arch flags, by @ryandesign
- ⬆️ build: highly upgraded meson build, by @lzutao
- 🏗 build: improved buck support, by @obelisk
- 🏗 build: fix
cmakescript : can create debug build, by @pitrou - 🏗 build:
Makefile: grep works on both colored consoles and systems without color support - 🏗 build: fixed
zstd-pgotarget, by @bmwiedemann - 👍 cli : support
ZSTD_CLEVELenvironment variable, by @yijinfb (#1423) - cli :
--no-progressflag, preserving final summary (#1371), by @terrelln - cli : ensure destination file is not source file (#1422)
- cli : clearer error messages, notably when input file not present
- doc : clarified
zstd_compression_format.md, by @ulikunitz - 🛠 misc: fixed
zstdgrep, returns 1 on failure, by @lzutao - misc:
NEWSrenamed asCHANGELOG, in accordance with fb.oss policy
-
v1.3.7 Changes
October 19, 2018🚀 This is minor fix release building upon v1.3.6.
The main reason we publish this new version is that @indygreg detected an important compression ratio regression for a specific scenario (compressing with dictionary at level 9 or 10 for small data, or 11 - 12 for large data) . We don't anticipate this scenario to be common : dictionary compression is still rare, then most users prefer fast modes (levels <=3), a few rare ones use strong modes (level 15-19), so "middle compression" is an extreme rarity.
🚀 But just in case some user do, we publish this release.A few other minor things were ongoing and are therefore bundled.
👍 Decompression speed might be slightly better with
clang, depending on exact target and version. We could observe as mush as 7% speed gains in some cases, though in other cases, it's rather in the ~2% range.🚀 The integrated backtrace functionality in the cli is updated : its presence can be more easily controlled, invoking
BACKTRACEbuild macro. The automatic detector is more restrictive, and release mode builds without it by default. We want to be sure the defaultmakecompiles without any issue on most platforms.📚 Finally, the list of man pages has been completed with documentation for
zstdlessandzstdgrep, by @samrussell .Detailed list of changes
- 👍 perf: slightly better decompression speed on clang (depending on hardware target)
- 🛠 fix : ratio for dictionary compression at levels 9 and 10, reported by @indygreg
- 🚀 build: no longer build backtrace by default in release mode; restrict further automatic mode
- 🏗 build: control backtrace support through build macro BACKTRACE
- misc: added man pages for zstdless and zstdgrep, by @samrussell
-
v1.3.6 Changes
October 05, 2018🚀 Zstandard v1.3.6 release is focused on intensive dictionary compression for database scenarios.
⚡️ This is a new environment we are experimenting. The success of dictionary compression on small data, of which databases tend to store plentiful, led to increased adoption, and we now see scenarios where literally thousands of dictionaries are being used simultaneously, with permanent generation or update of new dictionaries.
To face these new conditions, v1.3.6 brings a few improvements to the table :
- A brand new, faster dictionary builder, by @JenniferLiu, under guidance from @terrelln. The new builder, named fastcover, is about 10x faster than our previous default generator, cover, while suffering only negligible accuracy losses (<1%). It's effectively an approximative version of cover, which throws away accuracy for the benefit of speed and memory. The new dictionary builder is so effective that it has become our new default dictionary builder (
--train). Slower but higher quality generator remains accessible using--train-covercommand.
Here is an example, using the "github user records" public dataset (about 10K records of about 1K each) :
🏗 | builder algorithm | generation time | compression ratio | | --- | --- | --- | | fast cover (v1.3.6
--train) | 0.9 s | x10.29 | | cover (v1.3.5--train) | 10.1 s | x10.31 | | High accuracy fast cover (--train-fastcover) | 6.6 s | x10.65 | | High accuracy cover (--train-cover) | 50.5 s | x10.66 |🚤 Faster dictionary decompression under memory pressure, when using thousands of dictionaries simultaneously. The new decoder is able to detect cold vs hot dictionary scenarios, and adds clever prefetching decisions to minimize memory latency. It typically improves decoding speed by ~+30% (vs v1.3.5).
Faster dictionary compression under memory pressure, when using a lot of contexts simultaneously. The new design, by @felixhandte, reduces considerably memory usage when compressing small data with dictionaries, which is the main scenario found in databases. The sharp memory usage reduction makes it easier for CPU caches to manages multiple contexts in parallel. Speed gains scale with number of active contexts, as shown in the graph below :

Note that, in real-life environment, benefits are present even faster, since cpu caches tend to be used by multiple other process / threads at the same time, instead of being monopolized by a single synthetic benchmark.
Other noticeable improvements
A new command
--adapt, makes it possible to pipe gigantic amount of data between servers (typically for backup scenarios), and let the compressor automatically adjust compression level based on perceived network conditions. When the network becomes slower,zstdwill use available time to compress more, and accelerate again when bandwidth permit. It reduces the need to "pre-calibrate" speed and compression level, and is a good simplification for system administrators. It also results in gains for both dimensions (better compression ratio and better speed) compared to the more traditional "fixed" compression level strategy.
👍 This is still early days for this feature, and we are eager to get feedback on its usages. We know it works better in fast bandwidth environments for example, as adaptation itself becomes slow when bandwidth is slow. This is something that will need to be improved. Nonetheless, in its current incarnation,--adaptalready proves useful for several datacenter scenarios, which is why we are releasing it.✅ Advanced users will be please by the expansion of an existing tool,
tests/paramgrill, which has been refined by @georgelu. This tool explores the space of advanced compression parameters, to find the best possible set of compression parameters for a given scenario. It takes as input a set of samples, and a set of constraints, and works its way towards better and better compression parameters respecting the constraints.Example :
./paramgrill --optimize=cSpeed=50M dirToSamples/* # requires minimum compression speed of 50 MB/s optimizing for dirToSamples/* - limit compression speed 50 MB/s (...) /* Level 5 */ { 20, 18, 18, 2, 5, 2,ZSTD_greedy , 0 }, /* R:3.147 at 75.7 MB/s - 567.5 MB/s */ # best level satisfying constraint --zstd=windowLog=20,chainLog=18,hashLog=18,searchLog=2,searchLength=5,targetLength=2,strategy=3,forceAttachDict=0 (...) /* Custom Level */ { 21, 16, 18, 2, 6, 0,ZSTD_lazy2 , 0 }, /* R:3.240 at 53.1 MB/s - 661.1 MB/s */ # best custom parameters found --zstd=windowLog=21,chainLog=16,hashLog=18,searchLog=2,searchLength=6,targetLength=0,strategy=5,forceAttachDict=0 # associated command arguments, can be copy/pasted for `zstd`Finally, documentation has been updated, to reflect wording adopted by IETF RFC 8478 (Zstandard Compression and the application/zstd Media Type).
Detailed changes list
- 🏗 perf: much faster dictionary builder, by @JenniferLiu
- perf: faster dictionary compression on small data when using multiple contexts, by @felixhandte
- perf: faster dictionary decompression when using a very large number of dictionaries simultaneously
- cli : fix : does no longer overwrite destination when source does not exist (#1082)
- cli : new command
--adapt, for automatic compression level adaptation - api : fix : block api can be streamed with > 4 GB, reported by @catid
- api : reduced
ZSTD_DDictsize by 2 KB - api : minimum negative compression level is defined, and can be queried using
ZSTD_minCLevel()(#1312). - 🏗 build: support Haiku target, by @korli
- build: Read Legacy support is now limited to v0.5+ by default. Can be changed at compile time with macro
ZSTD_LEGACY_SUPPORT. - doc :
zstd_compression_format.mdupdated to match wording in IETF RFC 8478 - ⚡️ misc: tests/paramgrill, a parameter optimizer, by @GeorgeLu97
- A brand new, faster dictionary builder, by @JenniferLiu, under guidance from @terrelln. The new builder, named fastcover, is about 10x faster than our previous default generator, cover, while suffering only negligible accuracy losses (<1%). It's effectively an approximative version of cover, which throws away accuracy for the benefit of speed and memory. The new dictionary builder is so effective that it has become our new default dictionary builder (
-
v1.3.5 Changes
June 28, 2018🚀 Zstandard v1.3.5 is a maintenance release focused on dictionary compression performance.
🌲 Compression is generally associated with the act of willingly requesting the compression of some large source. However, within datacenters, compression brings its best benefits when completed transparently. In such scenario, it's actually very common to compress a large number of very small blobs (individual messages in a stream or log, or records in a cache or datastore, etc.). Dictionary compression is a great tool for these use cases.
🚀 This release makes dictionary compression significantly faster for these situations, when compressing small to very small data (inputs up to ~16 KB).

The above image plots the compression speeds at different input sizes for
zstdv1.3.4 (red) and v1.3.5 (green), at levels 1, 3, 9, and 18.
The benchmark data was gathered on anIntel Xeon CPU E5-2680 v4 @ 2.40GHz. The benchmark was compiled withclang-7.0, with the flags-O3 -march=native -mtune=native -DNDEBUG. The file used in the results shown here is theosdbfile from the Silesia corpus, cut into small blocks. It was selected because it performed roughly in the middle of the pack among the Silesia files.🐎 The new version saves substantial initialization time, which is increasingly important as the average size to compress becomes smaller. The impact is even more perceptible at higher levels, where initialization costs are higher. For larger inputs, performance remain similar.
👉 Users can expect to measure substantial speed improvements for inputs smaller than 8 KB, and up to 32 KB depending on the context. The expected speed-up ranges from none (large, incompressible blobs) to many times faster (small, highly compressible inputs). Real world examples up to 15x have been observed.
Other noticeable improvements
The compression levels have been slightly adjusted, taking into consideration the higher top speed of level 1 since v1.3.4, and making level 19 a substantially stronger compression level while preserving the
8 MBwindow size limit, hence keeping an acceptable memory budget for decompression.🏗 It's also possible to select the content of
libzstdby modifying macro values at compilation time. By default,libzstdcontains everything, but its size can be made substantially smaller by removing support for the dictionary builder, or legacy formats, or deprecated functions. It's even possible to build a compression-only or a decompression-only library.Detailed changes list
- perf: much faster dictionary compression, by @felixhandte
- perf: small quality improvement for dictionary generation, by @terrelln
- perf: improved high compression levels (notably level 19)
- 🚀 mem : automatic memory release for long duration contexts
- cli : fix :
overlapLogcan be manually set - cli : fix : decoding invalid lz4 frames
- 🐎 api : fix : performance degradation for dictionary compression when using advanced API, by @terrelln
- api : change : clarify
ZSTD_CCtx_reset()vsZSTD_CCtx_resetParameters(), by @terrelln - 🏗 build: select custom
libzstdscope through control macros, by @GeorgeLu97 - 🏗 build: OpenBSD support, by @bket
- 🏗 build:
makeandmake allare compatible with-j - doc : clarify
zstd_compression_format.md, updated for IETF RFC process - misc:
pzstdcompatible with reproducible compilation, by @lamby
Known bug
zstd --listdoes not work with non-interactive tty.
🛠 This issue is fixed indevbranch.